Share this:
Posted in:
UncategorizedFor ages, real-time infrastructure monitoring has been treated as the cornerstone of IT operations. Who wouldn’t want to know instantly when something goes wrong?
After all, if your only alternative is to be blissfully unaware of your problems, then of course real-time monitoring would be table stakes for a functioning IT department. But as infrastructure environments grow more complex, many teams are discovering that real-time monitoring alone leaves dangerous gaps in their observability strategy.
Why? Because it’s no longer a binary choice between ignorance and awareness.
There’s a third option: prevention.
Think of it like modern medicine. Would you rather rely solely on emergency room visits, or combine emergency care with preventive medicine and regular health monitoring?
The answer, of course, is both. Yet in IT infrastructure, we often focus exclusively on the equivalent of emergency response through real-time monitoring.
Let’s look at:
- Where Real-Time Monitoring Still Excels
- Where Real-Time Monitoring Gets Misapplied
- A Third Way: Predictive Monitoring
- Business Cost of Over-Relying on Real-Time Monitoring
Where Real-Time Monitoring Still Delivers Value
Before examining its limitations, let’s be clear about real-time monitoring’s essential role.
When catastrophic failures occur or critical systems go down, immediate alerts are non-negotiable.
Real-time monitoring proves invaluable for validating maintenance changes and providing instant feedback during troubleshooting. It’s particularly crucial for application-level monitoring where user impact requires immediate attention.
The problems arise when teams try to use real-time monitoring for tasks it wasn’t designed to handle. Modern infrastructure environments, with workloads spread across cloud, virtual, and physical platforms, are simply too complex for real-time alerts alone to be effective.
Three Misapplications of Real-Time Monitoring
1. The False Positive Nightmare
Modern infrastructure is designed to be resilient and self-healing, which creates an unexpected challenge for real-time monitoring. Many alerts end up being false positives, creating noise that obscures genuine issues.
When every minor fluctuation triggers an alert, teams become desensitized to warnings that truly matter.
A healthcare organization learned this lesson the hard way. Their infrastructure team was receiving over 280 capacity alerts every single week – one for each device approaching capacity thresholds.
Each alert generated a separate ticket requiring immediate response, creating a constant stream of interruptions that prevented the team from working on anything else. It wasn’t until they switched to predictive monitoring that they discovered a better way.
2. The Alert Fatigue Crisis
The flood of alerts creates more than just noise – it actively damages team productivity.
According to a 2023 Splunk survey of over 1,300 IT decision-makers, the average organization receives over 150,000 alerts per week. More concerningly, they found that 55% of these alerts are false positives, and 41% of teams waste significant time dealing with alerts that should have been automatically resolved.
When you’re drowning in notifications, it becomes nearly impossible to distinguish which ones truly need attention.
3. Surface-Level Understanding
Perhaps the biggest limitation of real-time alerts is their lack of context about what caused a problem. An alert might tell you that a device is experiencing high latency, but it can’t explain why it’s happening or what changed to cause it.
Finding these answers often requires hours of investigation while problems persist and users suffer.
One enterprise IT team encountered this limitation in a particularly painful way. Their VMware environment was experiencing periodic slowdowns that were affecting business operations.
Real-time monitoring clearly showed the high latency, but it couldn’t explain why it was happening. Even their vendors’ technical teams were stumped.
It took eight months of investigation before they finally discovered the root cause – a misconfiguration causing workload imbalances across their environment. Later, after implementing predictive monitoring with trend analysis, they were able to identify and prevent similar issues in minutes rather than months.
The difference wasn’t in the data being collected – it was in how that data was analyzed and presented.
Prevention Through Intelligence
When application monitoring detects an issue, infrastructure teams need to answer two fundamental questions:
- Have we run out of capacity? (Relatively east to answer)
- Have we run out of system performance? (Very difficult to answer)
Real-time monitoring struggles to effectively answer either question. Instead, teams need a differential diagnosis approach – comparing how systems are currently running with how they should be running.
Forward-thinking teams are moving beyond simple real-time alerts to embrace predictive analytics and trend analysis. By applying differential diagnoses to capacity and performance, predictive monitoring can spot warning signs days or weeks before traditional monitoring would detect an issue.
Take one example: A major airline discovered just how valuable this perspective could be when predictive monitoring helped them avoid a potential outage. An essential storage device appeared healthy at first glance, showing 40% free space. But trend analysis revealed a concerning pattern – the array’s data reduction rate was subtly declining in a way that wouldn’t trigger real-time alerts.
Looking deeper into the trend data, they discovered the array would actually run out of space within 30 days despite appearing to have plenty of capacity. This early warning gave them time to reallocate workloads and adjust data reduction settings, avoiding what would have been a $100,000 emergency storage purchase.
Without predictive monitoring, they would have discovered the problem only when the array reached a critical threshold – right on time for a real-time monitoring approach, but far too late to avoid expensive emergency measures.
The True Cost of Over-Relying on Real-Time Monitoring
The business case for moving beyond real-time monitoring becomes even clearer when we examine the numbers.
According to the Uptime Institute’s 2023 Global Data Center Survey, the average cost of an unplanned outage now exceeds $9,000 per minute. Yet the same institute found that 75% of outages are preventable with proper monitoring and maintenance.
When you consider that the typical outage lasts 30 minutes to 3 hours, the financial case for prevention – not just after-the-fact remediation – is even more compelling.
Or consider a scenario that plays out in enterprises every day: An application experiences slowdowns, triggering alerts from multiple monitoring tools. The cloud team sees healthy metrics in AWS. The storage team sees normal latency in their arrays. The virtualization team sees typical resource utilization in VMware. Yet users are still reporting problems.
Without unified visibility across platforms, each team wastes hours proving it’s not their problem instead of collaborating to find the true cause. This siloed approach often extends resolution times from minutes to days. Meanwhile, the business continues to suffer while teams debate where the problem lies.
How Visual One Fills the Gaps of Real-Time Monitoring
Let’s take a look at how Visual One Intelligence uses predictive analytics to do “differential diagnosis.”
Remember those two questions from earlier that infrastructure teams need to answer to stay ahead of problems?
- Have we run out of capacity? (Relatively east to answer)
- Have we run out of system performance? (Very difficult to answer)
Here are two screenshots from Visual One’s Enterprise Storage Summary. Notice that both questions are answered right away at the company level – and with just a few clicks, the team can drill down into the device level.

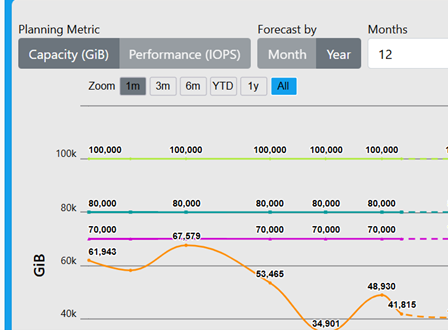
They are well within tolerance for both company and device. If they weren’t, this would be an immediate warning – which Visual One would also flag – that they should take preventative action to get ahead of any potential downtime risks.
On the other hand, if the team was experiencing downtime or a slowdown, this information would also be invaluable. It would tell the infrastructure team to rule out any misconfigurations (which Visual One would have flagged already). Then, if there are none, they can turn it back over the application team, confident that their infrastructure is running as it should be.
(This is the benefit of having both Application Monitoring and Infrastructure Monitoring. An APM tool has no significant ability to answer essential questions about whether infrastructure is running appropriately.)
Building a Complete Strategy
Cutting-edge infrastructure teams recognize the complementary nature of application and infrastructure monitoring.
Application monitoring excels at detecting immediate user impact, while infrastructure monitoring validates system health and prevents future problems. Neither alone provides the complete picture needed for modern environments.
This isn’t about abandoning real-time monitoring – it’s about properly maximizing it as just one component of a comprehensive strategy. By automating routine monitoring tasks, teams can focus more time on prevention and strategic improvements.
Engineers spend less time fighting fires and more time on strategic projects that drive business value. Budget waste from emergency purchases and unplanned downtime decreases significantly. User satisfaction improves as performance remains consistently strong rather than cycling through crisis and recovery.
After all, the best incident response is the one you never have to perform because you prevented the incident in the first place.
About Visual One Intelligence®
Visual One Intelligence® is an infrastructure tool with a unique approach—guaranteeing better & faster monitoring, observability, and FinOps insights by leveraging resource-level metrics across your hybrid infrastructure.
By consolidating independent data elements into unified metrics, Visual One’s platform correlates and interprets hybrid infrastructure data to illuminate cost-saving and operations-sustaining details that otherwise stay hidden.
These insights lead to fewer tickets, less downtime, lower costs, and more efficient architectures.










